Last week I had to give a conference about my research.
This was the introduction:
?Human language can be viewed as a system made of a finite number of units from where an infinite number of expressions is generated. Given any particular language, we have a finite and small number of phonemes, the distinctive sound units, that can be combined to form thousands of morphemes, with no upper bound to create new entries in the lexicon. Words themselves are combined to make up an infinite number of sentences.
When we learn a new language, or when we start to learn to speak, we are expected to learn the words that are more widely used first. In corpus linguistics we refer to this statistical property of words as word frequency. Our model focuses on a practical use of words based on their frequency. Words that have a higher frequency, that is, more occurrences in a given corpus we choose to represent a particular and real use of a language, appear in a higher number of sentences, hence they would be more useful to understand more sentences in a given language.
In order to grasp the meaning of a sentence, we also need to understand its syntax, the special relations that bind words together. Our model uses a very basic approach to syntax. We attempt to approximately determine which sentences would involve more processing in order to be efficiently parsed using words as units, sentence length the quantitative variable. We hence understand a sentence as a discrete variable made up of a number of words (tokens). We consider the number of words to be relevant for sentence complexity, defined here as the higher or lower number of syntactic rules we would need to efficiently parse a sentence. Long sentences involve more syntactic relations, so they are more difficult to parse than the shorter ones.?
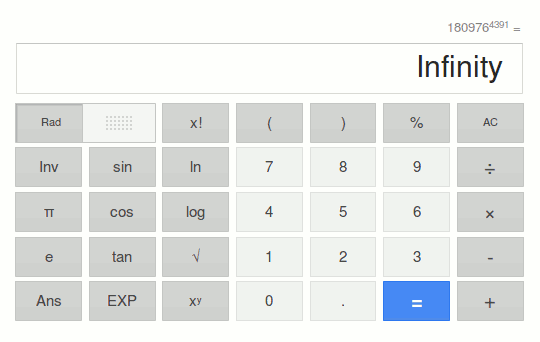
On the process of writing the presentation I began to work on an easy explanation on how from an initial finite number of phonemes, a countable number of syllables is formed to make up a finite, though boundless, number of words in a language. From there, I wanted to show that the number of sentences was infinite, so I made some basic operations taking maxima as values:
* Leaving obsolete words apart, the total vocabulary in a dictionary is considered relevant for combinatory purposes. Let's take
Oxford dictionaries as an example: 171,476 words in current use + around 9,500 derivatives: 180,976 words.
* Only lexemes are considered. Inflectional word-types and derivatives not listed in the dictionary are not counted.
* No grammatical restrictions are applied for the combination of words in a sentence.
* A sentence with an exceptional high number of words in English language is taken as the maximum value for the number of words in a sentence: Molly's monologue is 4,391 words (James Joyce).
The picture above shows the result of the final operation.